from neurovlm.data import fetch_data, load_latent
from neurovlm import NeuroVLM
# Fetch models and datasets
fetch_data()
Data fetch complete. Cache directory: /home/rph/.cache/huggingface/hub
'/home/rph/.cache/huggingface/hub'
Quickstart#
This tutorial introduces the high-level, inference-only API. It walks through text-to-brain and brain-to-text generation and retrieval.
Text-to-Brain: Generative#
# Initialize with CPU device explicitly
# On Mac, avoid device conflicts by using CPU
nvlm = NeuroVLM(device="cpu")
result = nvlm.text(["vision", "default mode network"]).to_brain(head="mse")
result.to_nifti() # returns list of nib.Nifti1Image
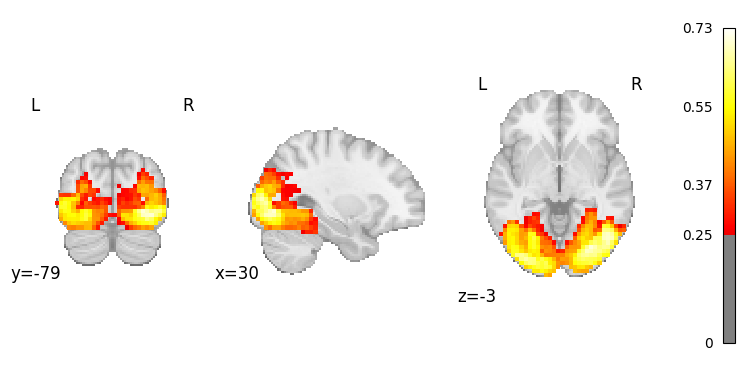
result.plot(0, threshold=0.25); # plot image for vision
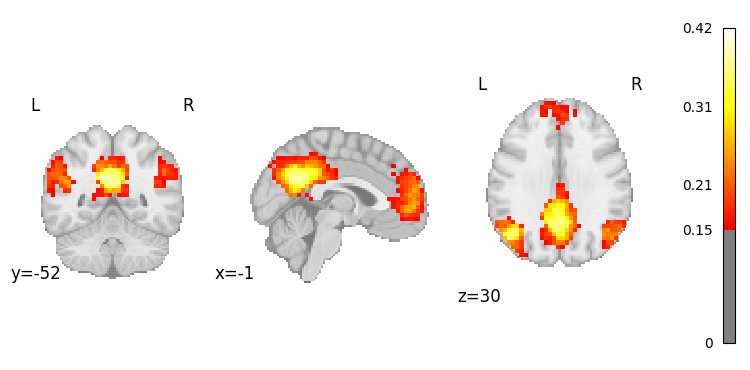
result.plot(1, threshold=0.15); # plot image for DMN
Text-to-Brain: Contrastive Ranking & Retrieval#
Contrastive models are used for ranking and retrieval. We can lookup similar neuroimages in a dataset, given a text query.
# Initialize with CPU device explicitly
nvlm = NeuroVLM(device="cpu")
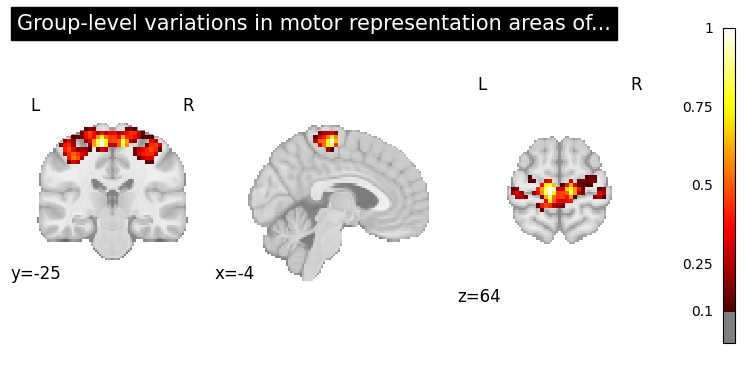
result = nvlm.text("motor").to_brain(head='infonce')
top = result.top_k(2) # each row pairs to a neuorimage that is most similar to the text query
top
Each row in the top dataframe above, is paried to an image that can be viewed.
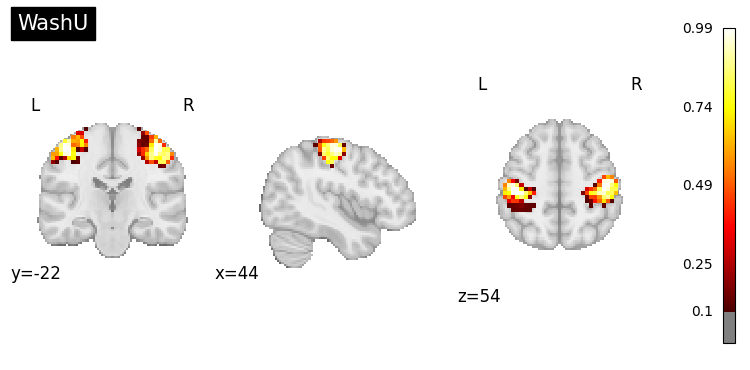
# WashU network atlas
top.plot_row(1, threshold=0.1);
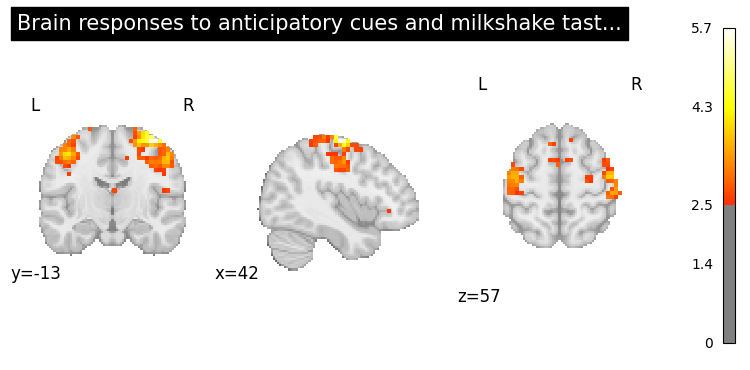
# NeuroVault
top.plot_row(2, threshold=2.5);
# PubMed
top.plot_row(4, threshold=0.1);
Brain-to-Text: Contrastive Ranking & Retrieval#
Here we use an auditory map as input from the Du atlas. We use the contrastive model to rank the most similar text across the datasets.
# Load networks examples images
networks = load_latent("networks_neuro")
# Initialize with CPU device explicitly
# Transform rank text based on auditory network
nvlm = NeuroVLM(device="cpu")
result = nvlm.brain(networks["Du"]["AUD"]).to_text()
result.top_k(5).query("cosine_similarity > 0.4") # return up to 5 examples per dataset
Brain-to-Text: Generative#
Below, we use the auditory map again. The contrastive model ranks the most similar text across the n-gram dataset. The top-k terms are then passed to an LLM for generation. Terms are a good target since they are short and faster for LLM to process. We could also have the LLM generation over related publications, but generation will be slower.
The LLM used below is very small and will produce poor results in many cases. To improve generation:
Customize the concept dataset to your priors.
Customize the system instructions for your domain/task.
Use a larger model, >= 7B parameters.
from neurovlm.retrieval_resources import _load_ngram, _load_latent_ngram
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load ngrams data
latent_ngram = _load_latent_ngram()
ngrams = _load_ngram() # to-do integrate ngram dataset into NeuroVLM class
# Top few terms based on cosine similarity, these will be passed to an LLM
cosine_similarity = result.query_embeddings[0] @ latent_ngram.T
indices_sorted = cosine_similarity.argsort(descending=True)
labels = ngrams[indices_sorted[:4]].tolist()
labels
['music', 'audio', 'sound', 'auditory regions']
# Generation
model_id = "HuggingFaceTB/SmolLM2-360M-Instruct"
# Use CPU explicitly to avoid device conflicts on Mac
device = "cpu"
dtype = torch.float32
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=dtype).to(device).eval()
if tok.pad_token_id is None:
tok.pad_token = tok.eos_token
messages = [
{"role": "system", "content": "Write a short paragraph explaing the following terms in the context of neuroimaging."},
{"role": "user", "content": "\n".join(labels)},
]
prompt = tok.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tok(prompt, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
out = model.generate(
**inputs,
max_new_tokens=128,
do_sample=False, # deterministic
num_beams=1, # deterministic
temperature=None, # ignored when do_sample=False
top_p=None,
pad_token_id=tok.eos_token_id,
eos_token_id=tok.eos_token_id,
)
new_tokens = out[0, inputs["input_ids"].shape[-1]:]
print(tok.decode(new_tokens, skip_special_tokens=True))